Your final station of understanding multiplexed I/O
Table of Contents

Introduction
To explain multiplexing, let’s follow the popular approach of comparing to its plain old predecessor, First, we’ll discuss the disadvantages of traditional network I/O to highlight the advantages of multiplexed I/O.
To keep things simple, all the code snippets here are pseudocode—understanding their purpose is sufficient. Let’s rock!
Blocking IO
In ancient times (or when an innocent programmer wrote code), a server might write code like this to handle client connections and requests:
1listenfd = socket(); // Open a network communication port
2bind(listenfd); // Bind it
3listen(listenfd); // Listen for connections
4while(1) {
5 connfd = accept(listenfd); // Block until a connection is established
6 int n = read(connfd, buf); // Block to read data
7 doSomeThing(buf); // Do something with the read data
8 close(connfd); // Close connection, loop to wait for next connection
9}This code will run sluggishly, like so:

Old “Steam engine” doing IO
As shown, the server thread blocks at two points: the accept function and the read function. If we look further into read, we find it blocks in two stages:

Read blocks in two stages.
This is traditional blocking I/O, as illustrated below:
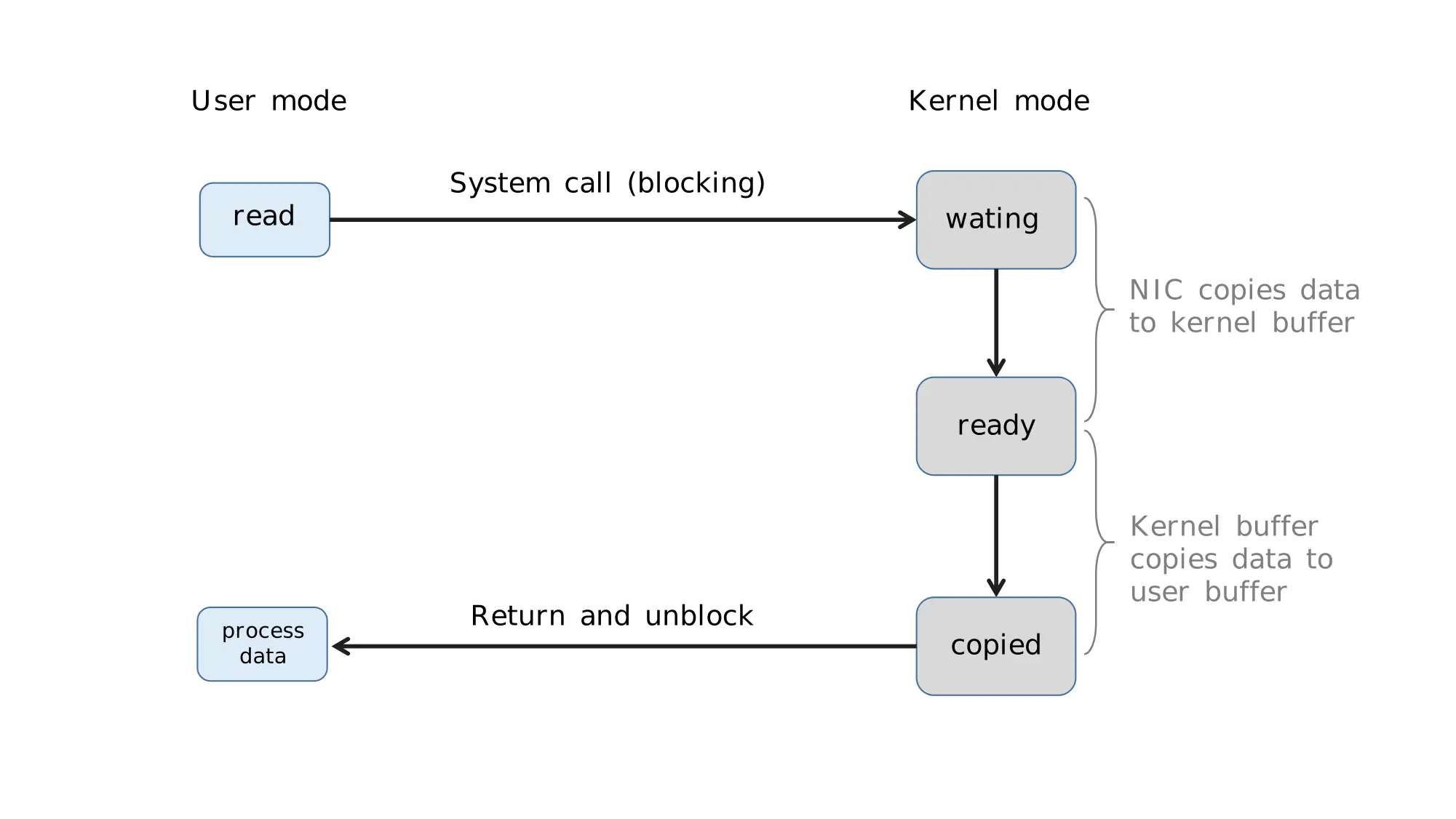
Blocking IO workflow
With that clearified, consider this situation: What if a connected client maliciously doesn’t send any data? Answer is: The server thread will stay blocked at read indefinitely, thus getting unable to accept any other connections. Abandon ship!!
Non-blocking IO
To address this problem, we need to change the read function. A clever solution is to create a new process or thread each time we call read to handle business logic:
1while(1) {
2 connfd = accept(listenfd); // Block to establish connection
3 pthread_create(doWork); // Create a new thread
4}
5
6void doWork() {
7 int n = read(connfd, buf); // Block to read data
8 doSomeThing(buf); // Process the data
9 close(connfd); // Close connection and wait for next one
10}This way, the server can immediately accept new connections without being blocked by a client’s slow request.

Thread based non-blocking solution
However, this isn’t truly non-blocking I/O — It just uses multithreading to avoid blocking the main thread on read. The read function provided by the OS is still blocking. True non-blocking I/O requires an actual non-blocking read function from the OS. With this, if no data has arrived (reached the network card and copied to the kernel buffer), it returns an error (e.g. -1) instead of waiting.
To use this functionality, we simply set the file descriptor to non-blocking mode before calling read(supported feature in OS):
1fcntl(connfd, F_SETFL, O_NONBLOCK);
2int n = read(connfd, buffer) != SUCCESS;This way, the user thread must call read repeatedly until it returns a non-error value, then proceed with business logic.

Non-blocking read
Note: non-blocking read means that if data hasn’t reached the network card or been copied to the kernel buffer, this stage is non-blocking. However, once data is in the kernel buffer, read remains blocking, waiting for the data transfer to complete.
I/O Multiplexing
Creating a thread for each client can quickly exhaust server resources.
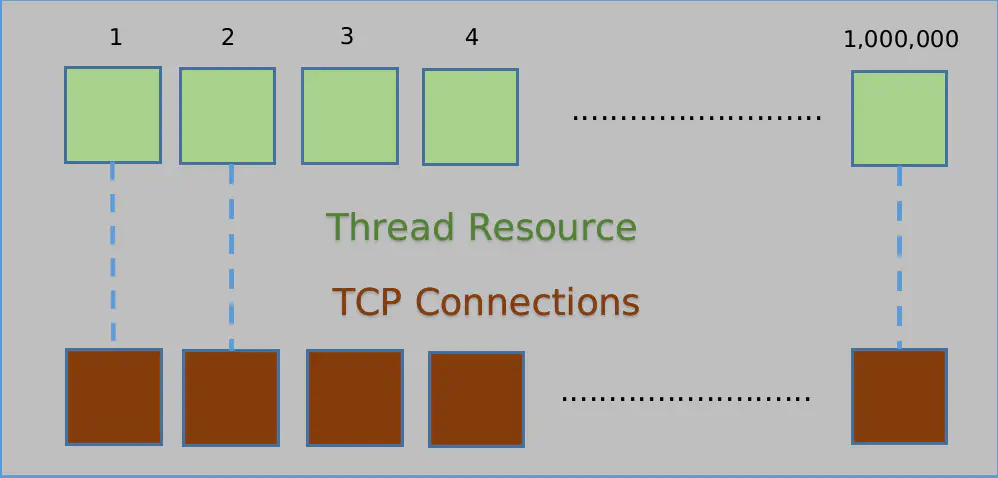
Another clever solution is to add each accepted client’s file descriptor (connfd) to an array:
1fdlist.add(connfd);Then, use a new thread to iterate over this array, calling each element’s non-blocking read:
1while(1) {
2 for(fd in fdlist) {
3 if(read(fd) != -1) {
4 doSomeThing();
5 }
6 }
7}This way, we successfully handled multiple client connections with just one thread.

Handle many connections with one thread.
Cool! This looks like multiplexing, doesn’t it? Well, not really. Just like using multithreading to make blocking I/O seem non-blocking, this approach is simply a user-level trick. Each time read returns -1, it’s still a wasted system call. It’s like making RPC requests in a while loop in distributed systems—it’s inefficient.
To truly solve this, we need the OS to provide a function that can pass multiple file descriptors to the kernel, allowing it to handle the looping internally, which is way more efficient than in user mode. Let’s dive in these functions and get more insights.
Select
The select function, provided by the OS, allows us to pass an array of file descriptors, letting the OS check which can be read or written, then tells us which to process.
The function has the following definition:
1int select(
2int nfds,
3fd_set *readfds,
4fd_set *writefds,
5fd_set *exceptfds,
6struct timeval *timeout
7);- nfds: Highest-numbered file descriptor in the monitored set, plus one.
- readfds: Set of descriptors to monitor for reading.
- writefds: Set of descriptors to monitor for writing.
- exceptfds: Set of descriptors to monitor for exceptions.
- timeout: Timeout value (three options: NULL to wait indefinitely, specified time to wait, check ready status once and return immediately).

Illustration of how select works
Now the server code can look like this:
First, a thread continuously accepts connections and adds the socket descriptor to a list.
1while(1) {
2 connfd = accept(listenfd);
3 fcntl(connfd, F_SETFL, O_NONBLOCK);
4 fdlist.add(connfd);
5}Then, another thread calls select, passing this list to the OS to handle looping.
1while(1) {
2 //nready means how many in the arrayare ready.
3 //And parameters of select are simplified.
4 nready = select(list);
5 ...
6}Looks neat! But remember, after select returns, the user still needs to iterate over the list passed to the OS. But with the OS marking out ready descriptors for you, there’s no more wasted system calls.
1while(1) {
2 nready = select(list);
3 // User still needs to loop over the list
4 for(fd : fdlist) {
5 if(fd.ready != -1) {
6 // only ready ready fds
7 read(fd, buf);
8 // 'nready' fds can be read, so stop when they are all checked
9 if(--nready == 0) break;
10 }
11 }
12}Take a look at this animation again. Things are starting to make sense right?
Select animation again
You can see a few details:
-
The
selectcall requires passing in an fd array, which needs to be copied to the kernel. In high-concurrency scenarios, this copying consumes a significant amount of resources.
Possible improvement: Avoid copying. -
In the kernel,
selectstill checks the readiness of file descriptors through iteration, which is a synchronous process. However, it doesn’t incur the cost of switching contexts for system calls
Possible improvement: Use asynchronous event notifications. -
selectonly returns the count of readable file descriptors; the user still has to iterate to identify which are ready.
Possible improvement: Only return ready fds.
The entire select process is illustrated below.
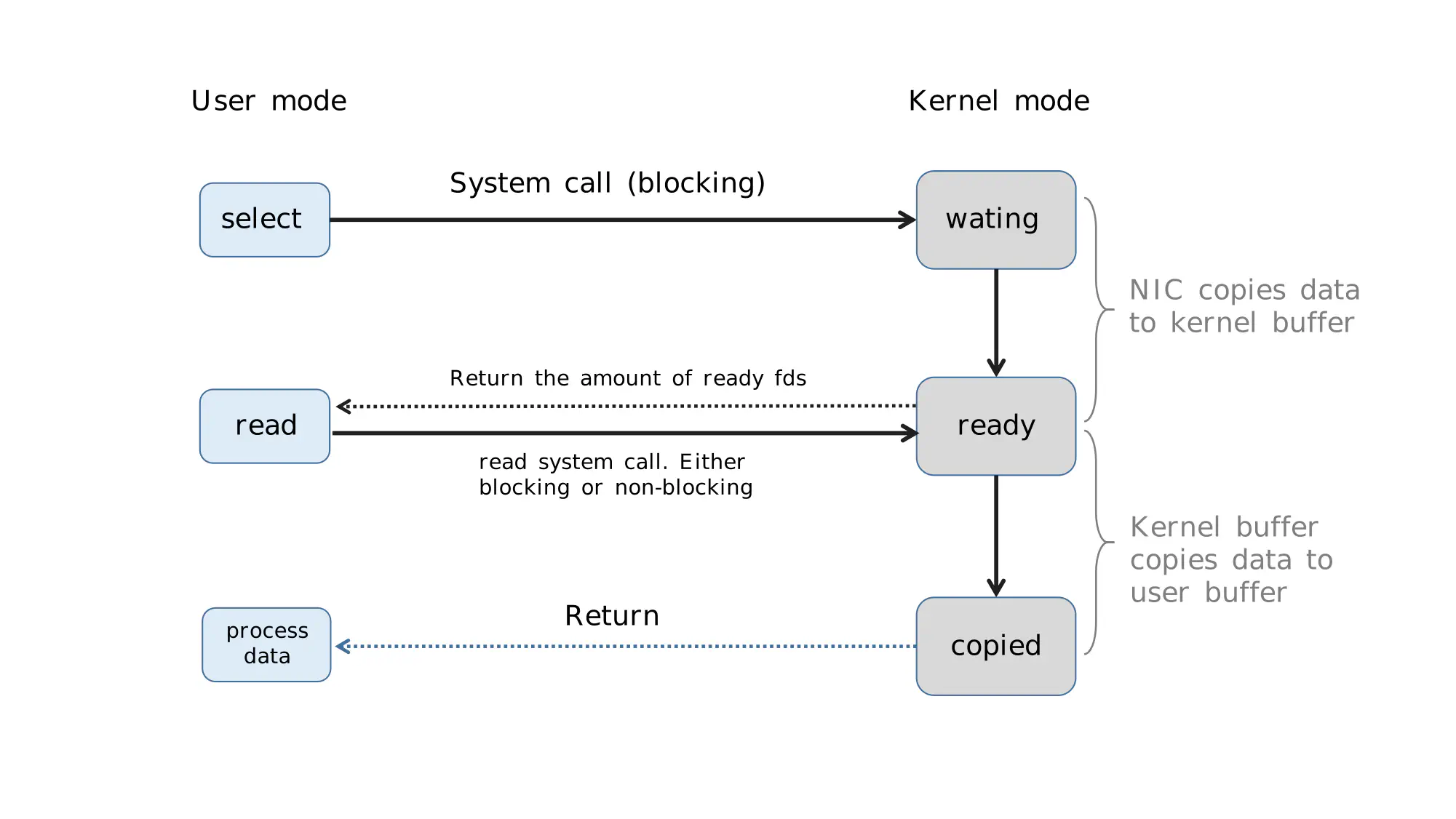
Select execution steps
This approach allows a single thread to handle multiple client connections (file descriptors) and reduces the overhead of system calls (since multiple file descriptors require only one select system call and limited read system calls for those ready file descriptors).
poll
The operating system provides another alternative to select function: poll.
The poll function is absolutely the same as select. The only exception is that, it removes the limit on the number of file descriptors(1024) that can be passed in.
epoll
epoll is the ultimate solution, addressing select and poll’s issues. Remember the 3 problems above with select? epoll improves them all:
- The kernel saves a copy of the file descriptor set, so users don’t need to pass it every time.
- The kernel uses asynchronous I/O events instead of looping.
- It only returns file descriptors with I/O events, avoiding user-level iteration.
To be precise, the OS provides the following 3 functions for epoll:
- Create an epoll handle:
1int epoll_create(int size);- Add, modify, or delete file descriptors to monitor:
1int epoll_ctl(
2 int epfd, int op, int fd, struct epoll_event *event
3);- A bit similar to
select:
1int epoll_wait(
2 int epfd, struct epoll_event *events, int max_events, int timeout
3);Using these functions, it now works as smooth as the following animation:

Missing gif to show epoll
Summing up
In plain terms:
It all started because the read function, provided by the operating system, is blocking by nature. We call this Blocking IO. To avoid the main thread getting stuck, programmers initially used multithreading at the user level to prevent this.
Later, the operating system realized that this was a common need, so it introduced a non-blocking read function at the system level. This allowed programmers to read from multiple file descriptors in a single thread, which we call Non-blocking IO.
However, reading from multiple file descriptors still requires iteration. As high-concurrency scenarios increased, the number of file descriptors that needed to be iterated over in the user space also grew, leading to more system calls within the while loop. This could lead to a huge waste of system resource.
As this demand continued to rise, the operating system then provided a mechanism to iterate over file descriptors at the system level. This is called IO multiplexing.
There are three main functions for multiplexing: it began with select, then poll was created to remove select’s file descriptor limitations, and finally epoll was developed to address the three limitations of select.
So, the evolution of IO models reflects changing times, pushing the operating system to add more functionality to its kernel.
Once you understand this thinking, you’ll easily spot some misconceptions going around. For example, many articles claim that the efficiency of multiplexing lies in a single thread’s ability to monitor multiple file descriptors. But this explanation only scratches the surface: Looping through file descriptors using non-blocking read function is also a way to monitor multiple fds in one thread.
The true reason multiplexing works efficient is that the operating system provides this system call, converting multiple system calls within the while loop into a single system call + kernel-level iteration over the file descriptors.
It’s similar to when we write business code: Instead of using a loop to call an http endpoint and process data once in a call, we switch to using a batch interface, enabling a single request to handle batch processing all at once.
Same principle.
comments powered by Disqus