You call this stupid thing advanced load balancing?
Table of Contents
Introduction
In the previous article, we introduced the basics of load balancing through the story of Ryan’s startup. After several iterations and optimizations, Ryan implemented NGINX load balancing, dynamic-static content separation, and a master-slave architecture, enabling his system to handle a significant number of requests. However, with the growing success of his business, customers from across the country began visiting his website, and the surge in traffic drastically slowed it down. It took over 5(!) seconds to load a page, and during peak times, the site even became inaccessible. Even he added more tomcat instances, things didn’t change much. It’s time for an “advanced” version of load balancing!
Problem analysis
Ryan examined all the servers and summarized the server load. It turned out that while most servers had a relatively normal resource and CPU load, NGINX was consistently running at almost 100%. That’s a clear signal—NGINX is the bottleneck! But how exactly does this happen? To understand this, let’s review the different layers of the network:
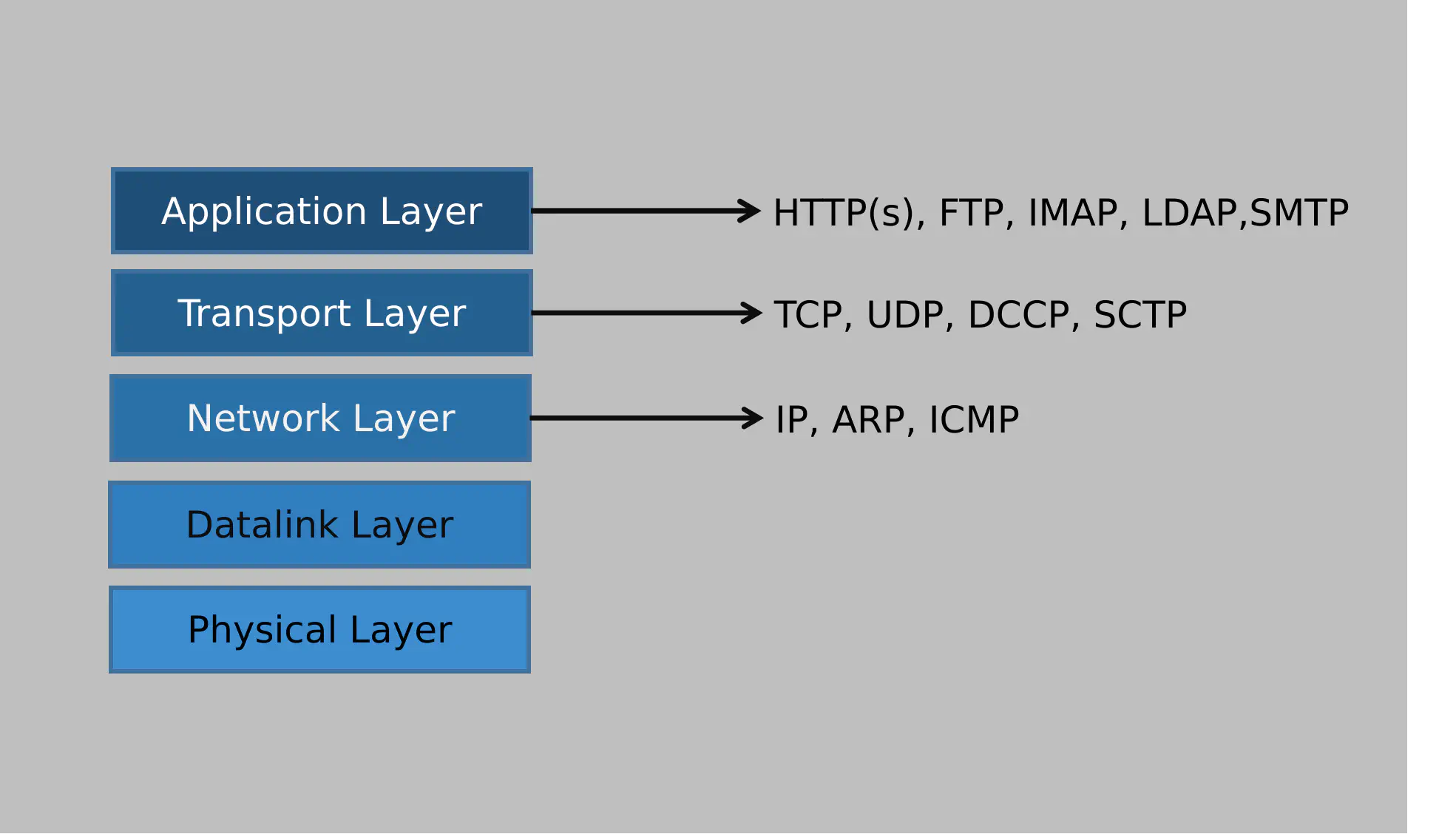
Layers and some of their corresponding protocols
You may have heard the saying that one network device or software operates on Layer 2 (Data Link), while another works on Layer 3 (IP)1. This essentially means: Which protocol can this device understand and possibly manipulate? For example, a Layer 2 switch only understands data frames and directs these frames to different (physical) ports based on the destination MAC address. In contrast, a Layer 3 switch understands IP addresses and routes IP packets to different (again physical) ports based on the IP address.
However, when we look at a router, which also operates on Layer 3, it not only routes IP packets within your LAN according to their IP address but also repackages your data, proxies your request to the internet, and returns the result to you. In this case, the router is also manipulating IP packets.
With that understood, let’s turn to NGINX. NGINX processes HTTP(S) requests and understands which URL is being requested. It then connects to the configured upstream server based on this URL, retrieves the data, and finally sends the data back to the client. Since HTTP operates at the application layer, NGINX is considered an application-layer(Layer 72) load balancer. So far, so good.
But the problem is: For each request, it establishes two TCP connections: one with the client and the other with the upstream server. TCP connections consume memory and other system resources (for TCP sockets, buffers, etc., as explained in this post). So, as the number of connections grows (e.g., into the millions), NGINX’s ability to handle the load drops significantly.
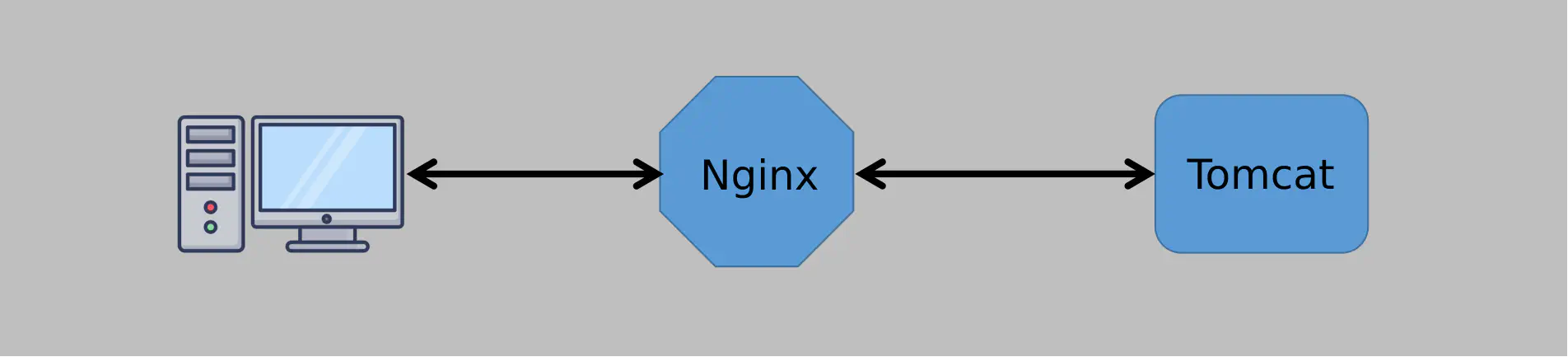
What if there were a load balancer that simply forwarded packets, like a router, without the need to establish connections? By avoiding the overhead of maintaining TCP connections, its capacity to handle traffic would be greatly increased. Well, surely there is a such fancy thing! Let’s finally take a look at Ryan’s saving grace: LVS, a Layer 4 load balancer.
Observing http traffic from a lower perspective
An HTTP connection is essentially a TCP connection that transfers HTTP content. Nginx, as a Layer 7 application, focuses on Layer 7 protocols (such as HTTP). As mentioned earlier, LVS operates at Layer 4, which means it deals with protocols like TCP and can perform similar forwarding or manipulation tasks as a router. However, it introduces a much more interesting effect.
So how does a layer 4 load-balancer work?
Let’s break it down step by step:
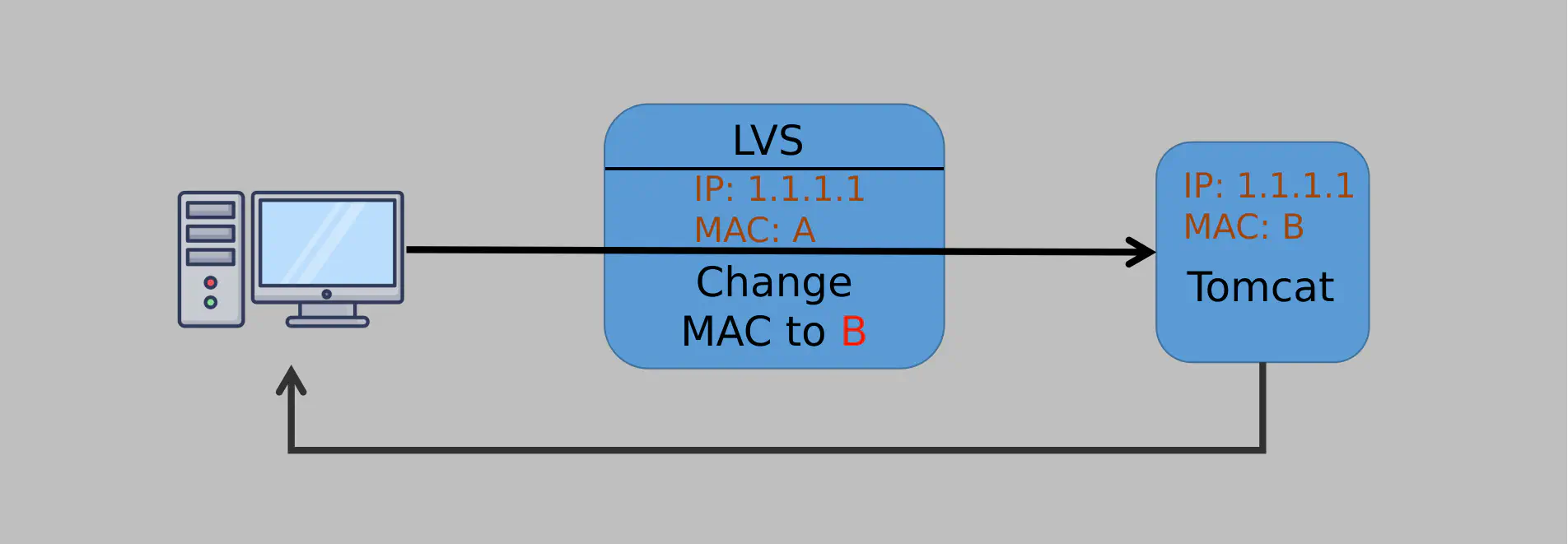
- When LVS receives the first SYN request (TCP initiation) from a client, it selects the optimal server based on its load-balancing algorithm.
- It then modifies the target MAC address in the packet (changing it to the backend server’s MAC address) and forwards it to the server. While each of the servers has a different real IP, they also share the same IP as LVS (configured in a special way).
- When a server receives the LVS-forwarded packet, it believes it is the intended recipient since both the IP and MAC addresses match its configuration.
And now the magic happens: The server processes the request and responds directly to the client, bypassing LVS! This has a major advantage: LVS only forwards the data to the servers without maintaining any state. This makes LVS much more efficient than Nginx. Take a look at the following diagram for comparison:
In conclusion, we added an LVS layer on top of Nginx to handle all traffic. To ensure high availability for LVS, it is deployed in an active-passive configuration, similar to the Nginx setup. With this design, if Nginx’s capacity isn’t sufficient, we can easily scale horizontally. Our architecture evolved as follows:
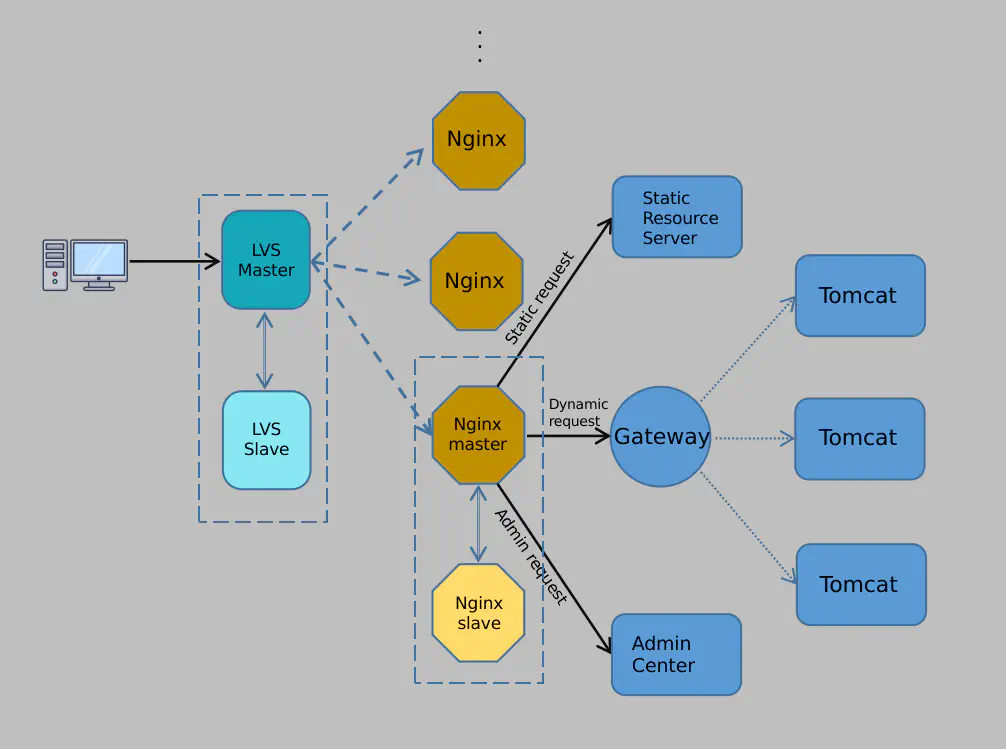
Of course, a single LVS instance wouldn’t be able to handle large traffic volumes. The solution is to add more servers and use DNS load balancing. DNS randomly assigns traffic to one of the LVS instances during domain name resolution, as shown here:
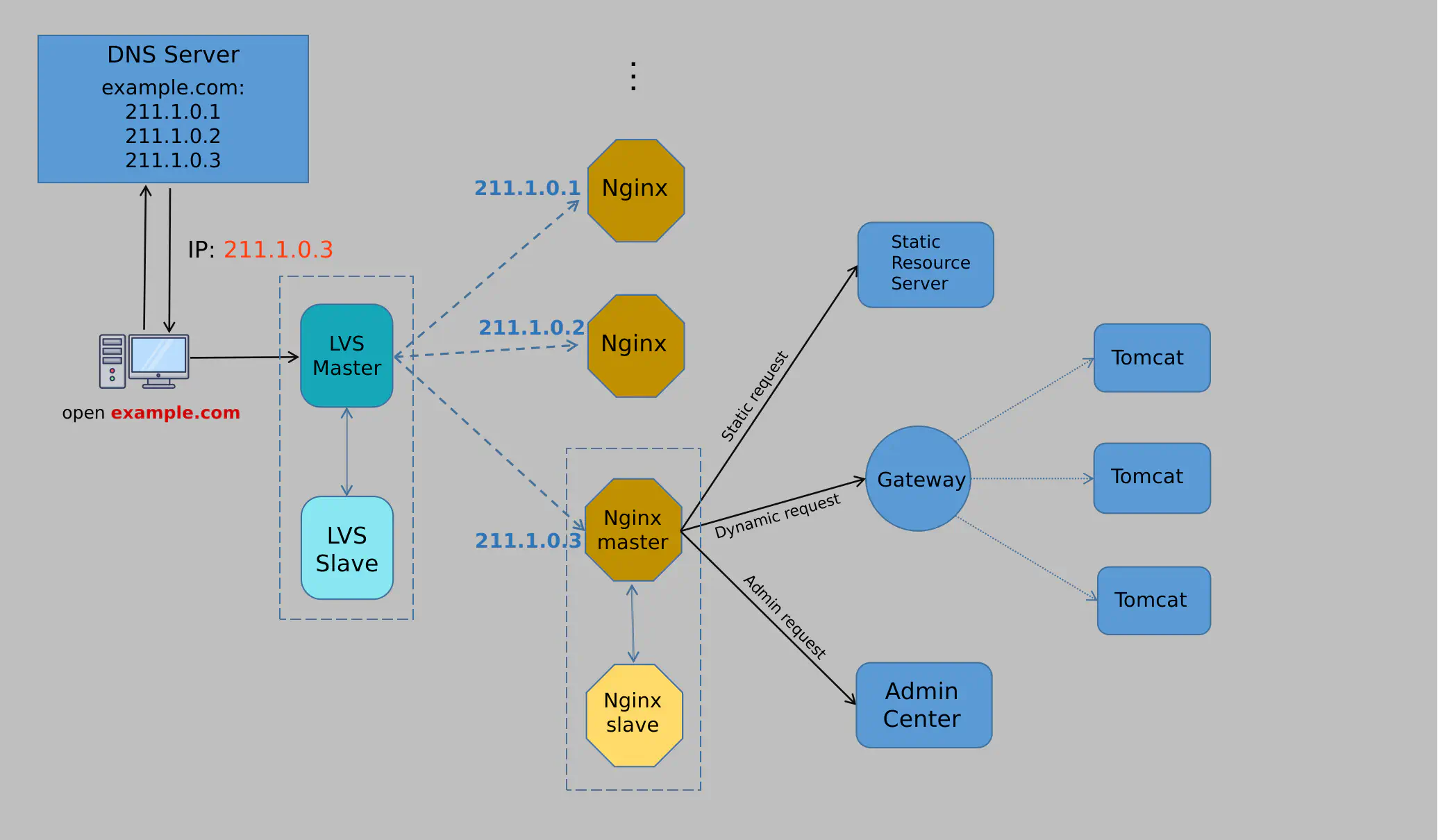
This approach finally stabilized the traffic flow…for now.
Conclusion
Architecture design must be tailored to the actual business situation. Discussing architecture without considering business needs is pointless. Each evolution of the architecture mentioned above closely aligns with the business’s growth. For small to medium businesses with modest traffic, Nginx alone as a load balancer is sufficient. As traffic grows, consider using LVS + Nginx. For companies with massive traffic, like Alibaba (with tens of Gbps of traffic and millions of concurrent connections), even LVS wasn’t enough. There are companies developing their own layer 4 load balancer when facing these situations.
I hope this article has given you a better understanding of the concept of layering, which ensures each module has a clear responsibility, making the system more modular, easier to extend, and decoupled. The TCP/IP protocol is a great example—each layer is responsible for its own tasks, and higher layers don’t care about the implementation details of the lower layers.
-
A device or software is not limited to work on just one layer. It could very well work in different mode and thus handle multiple layers, for example firewall. ↩︎
-
According to OSI model, there is indeed 7 layers. But in reality OSI is considered too sophisticated. That’s why TCP/IP model became the practical standard, in which the 5th, 6th and 7th layer is seen as one. ↩︎
comments powered by Disqus