You call this stupid thing load balancing?
Table of Contents
Introduction x
Have you ever wondered what exactly happened in the whole internet infrastructure when you enter a keyword in amazon and press enter? How many devices are diligently serving you, so that you see that fancy page with your search result? And at any time, there is a huge amount of people using amazon, how does it handle such tremendous volume?
This is a tough question, as it involves a range of concepts and mechanisms such as HTTP, TCP, gateways, LVS, and many more protocols. If you can master each of these concepts, it will significantly boost your skillset and give you a deep understanding of how the internet works. Even if you can’t fully grasp everything, knowing how traffic flows will be extremely helpful for troubleshooting issues. In fact, I’ve used this knowledge to diagnose many problems in the past. To get a full understanding of the process, I’ve researched extensively, and I try my best to explain it clearly. However, as I started writing, I realized the content would be too long. So I’m splitting it into two parts. In this post, I will introduce the overall backend architecture, and in the next post, I’ll dive into the details of components like LVS, NAT, and how switches and routers work. I believe this will be helpful for everyone.
Disclaimer: This design reflects by no means how amazon works. Amazon is just a random example.
Story of a startup business
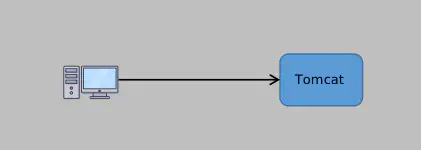
Once upon a time, a guy named Ryan started his own business and made a cool website for his customers. In the early days, since there wasn’t much traffic, Ryan only deployed a single Tomcat server, letting clients send requests directly to this server. Clean!
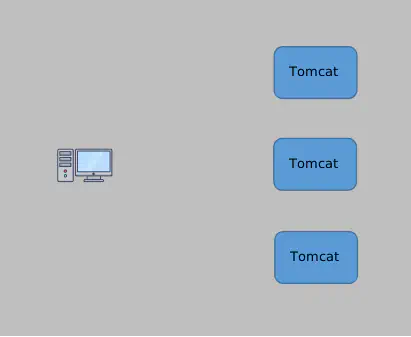
Initially, this setup worked fine because the business volume wasn’t large. A single machine could handle the load. However, as Ryan’s service was so attractive, his business quickly gained momentum. The performance of this single server started hitting its limits. Furthermore, because only one machine was deployed, if it went down, the entire business would crash, which was unacceptable. To avoid the performance bottleneck of a single server and mitigate the risk of a single point of failure, Ryan decided to deploy multiple machines (let’s say three). This way, the client could randomly connect to one of the servers. If one server went down, the others would still be operational, and the client could be routed to another active machine. Neat!
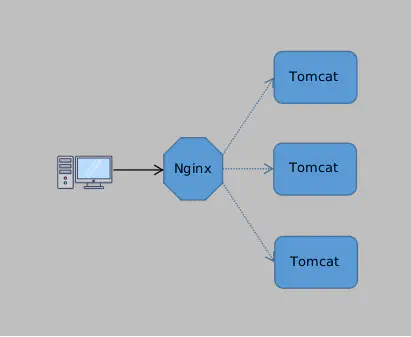
But here’s the problem: How does the client know which of the three machines to connect to? It would be a disaster to let the client decide itself because he would have to know all available servers and then randomly connect using something like round-robin. If one server crashed, the client wouldn’t know in advance and might still connect to the dead server. So, the task of selecting which server to connect to is best handled on the server side. How should this be done? In architecture design, there’s a classic saying: “There’s nothing that can’t be solved by adding one more layer. If there is, just add another one.” So, we add a layer on the server side, which we call LB (Load Balancer). The LB receives all client requests and decides which server to communicate with. In practice, Nginx is often used as the LB.
With this architecture, the business was able to grow rapidly. However, soon after, Ryan noticed a problem: All traffic was reaching the servers directly, which wasn’t a secure design. Could there be a layer of authentication before traffic hits the servers? Certainly! We call this additional layer the gateway (and to avoid single point of failure, the gateway should also be deployed in a clustered form). With gateway deployed, only authenticated traffic would be allowed to reach the servers.
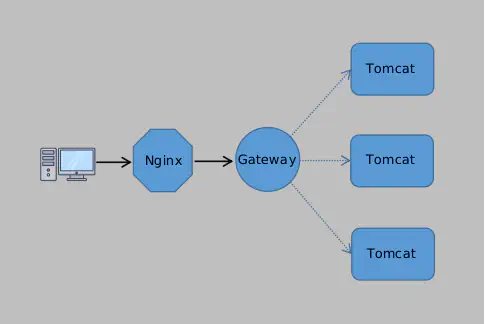
Now, all traffic has to pass through the gateway layer before hitting the servers. If authentication passes, the gateway forwards the traffic to the servers. Otherwise, it returns an error directly to the client. Beyond authentication, the gateway also handles risk control (e.g., blocking spam bots), protocol conversion, and traffic management to ensure that only secure and manageable traffic reaches the servers. Safe!
This architecture held up well for quite a while. But eventually, Ryan noticed another problem: Both dynamic requests and static resources (like JavaScript and CSS files) were being retrieved from Tomcat. Under high traffic, this put a huge load on Tomcat. In fact, Tomcat isn’t as efficient at handling static resources as Nginx is. Tomcat loads files from disk every time, which impacts performance dramatically, while Nginx can use proxy caching to greatly enhance its ability to handle static resources.
Note: Proxy cache refers to Nginx caching resources from a static resource server in its local memory and disk. If a subsequent request hits the cache, Nginx directly returns the resource from its local cache.
With this in mind, Ryan made the following optimization: Dynamic requests go through the gateway to Tomcat, while static requests are handled by Nginx and sent to the static resource server.
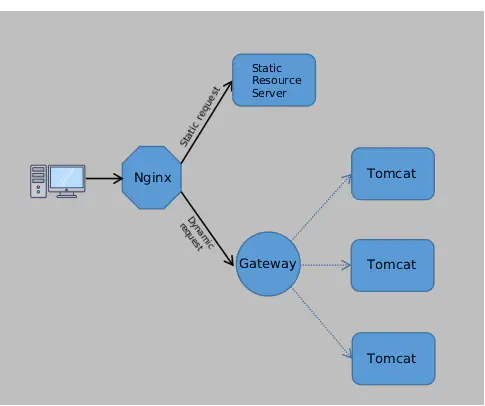
This separation of static and dynamic requests allows Tomcat to focus on what it’s best at: Handling dynamic requests, while Nginx, leveraging its proxy cache and other features, improves the backend’s capacity to handle static resources. Efficient!
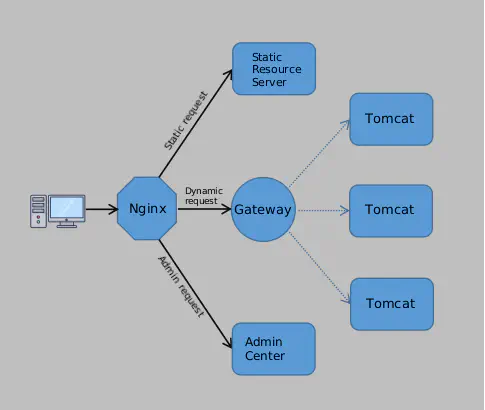
It’s also important to note that not all dynamic requests need to pass through the gateway. For instance, requests to the backend admin center, which are used by internal employees, don’t follow the same authentication rules as the API requests at the gateway. So, two admin center servers were directly deployed, and Nginx routes admin requests to these servers, bypassing the gateway altogether.
To prevent a single point of failure, Nginx was deployed in an active-passive setup. The secondary Nginx monitors the primary Nginx using a keepalived mechanism (sending heartbeat packets), and if the primary goes down, the secondary takes over immediately.
This architecture worked well, but Nginx, being a Layer 7 (application layer) load balancer, has limitations. It establishes a TCP connection with the client before forwarding the request, and it also needs to establish a TCP connection with the upstream server. TCP connections consume memory (for TCP sockets, buffers, etc.), so as the number of connections grows (e.g., to millions), Nginx’s ability to handle the load drops significantly.
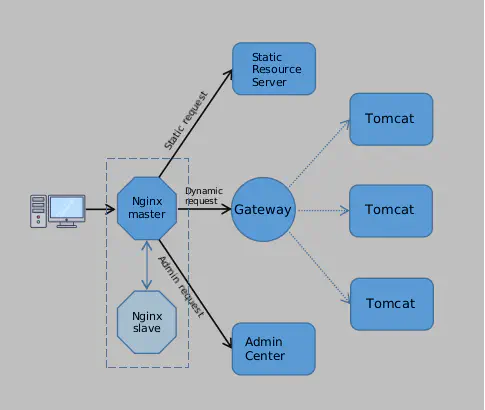
Finally, now Ryan’s architecture is secure, efficient, and highly available! For his moderate business size, this would guarantee a good service quality.
Is that the end?
While the design above suffices for Ryan, it’s certainly not the end of load balancing. Some consideration to take away:
- Nginx works on HTTP level. So it needs to maintain two connections(one with client, one with tomcat) for each request. And according to my previous post, these connections take up system resources. As Ryan’s business gets bigger, this might be a bottleneck.
- When Ryan plans a sales action, which starts on 1st November 0 o’clock, requests from the whole country(even whole world) might rush in at exactly 0:00. In worst cast, the website might not even load correctly.
- Let’s say Ryan is actually Jeff Bezos and the business becomes world-wide, how can requests from the whole world be balanced correctly?
Hopefully this article has brought you some insights in system design. In the next article I will try to address some of these points.
comments powered by Disqus